Testing
Introduction
We begin with a short program and simple question: Is the following program correct?
#include <stdio.h>
// Conversion from quarts to liters
const float quarts_per_liter = 1.056710f;
int main() {
// input
float quarts;
float liters;
int numAssigned;
printf("Enter a value: ");
numAssigned = scanf("%f", &quarts);
// validate input
if(numAssigned == 0) {
printf("Error: Unable to read number\n");
return 1;
} else if(quarts < 0) {
printf("Error: Cannot have a negative quantity");
return 1;
}
// process value read
liters = quarts / quarts_per_liter;
// output
printf("Result: %f quarts = %f liters\n", quarts, liters);
return 0;
}
The answer is “Maybe. The program may or may not be correct”; to expand, the correctness of this program depends upon what problem is to be solved.
The program is correct, if:
- one is trying to convert a value in quarts to the corresponding value of liters, and
- the
floatdata type has adequate precision.
However, the program is incorrect otherwise. For example:
- The program likely is not correct if we want 25 digits of accuracy in the answer.
- The program certainly is not correct if the problem was to determine whether or not it will rain tomorrow.
Point: Discussions about problems and their solutions depend on a careful specification of the problem.
Pre- and Post-Conditions
To solve any problem, the first step always should be to develop a clear statement of what initial information may be available and what results are wanted. For complex problems, this problem clarification may require extensive research, ending in a detailed document of requirements.
One Grinnell faculty member has commented on seeing requirements documents for a commercial product that filled 3 dozen notebooks and occupied about 6 feet of shelf space. However, noted software engineering professor Mark Ardis has quipped that
A specification that will not fit on one page of 8.5x11 inch paper cannot be understood.
Within the context of introductory courses, assignments often give reasonably complete statements of the problems under consideration, and a student may not need to devote much time to determining just what needs to be done. In real applications, however, software developers may spend considerable time and energy working to understand the various activities that must be integrated into an overall package and to explore the needed capabilities.
Once an overall problem is clarified, a natural approach in Scheme or C programming is to divide the work into various segments, often involving multiple functions. For each region of code, we need to understand the information we will be given at the start and what is required of our final results.
Pre-Conditions are constraints on the types or values of its arguments. Post-conditions specify what should be true at the end of a procedure. In Racket or C, a post-condition typically is a statement of what a procedure should return.
A more general concept is an assertion, which is a statement about variables at a specified point in processing. A pre-condition is an assertion about variable values at the start of processing, and a post-condition is an assertion at the end of a code segment.
It is good programming style to state the pre- and post-conditions for each procedure or function as comments.
Pre- and Post-Conditions as a Contract
One can think of pre- and post-conditions as a type of contract between the developer of a code segment or function and the user of that function.
- The user of a function is obligated to meet a function’s pre-conditions when calling the function.
- Assuming the pre-conditions of a function are met, the developer is obligated to perform processing that will produce the specified post-conditions.
As with a contract, pre- and post-conditions also have implications concerning who to blame if something goes wrong.
-
The developer of a function should be able to assume that pre-conditions are met.
-
If the user of a function fails to satisfy one or more of its pre-conditions, the developer of a function has no obligations whatsoever—the developer is blameless if the function crashes or returns incorrect results.
The Software Engineering Code of Ethics and Professional Practice tempers this hyperbolic assertion somewhat:
Approve software only if they have a well-founded belief that it is safe, meets specifications, passes appropriate tests, and does not diminish quality of life, diminish privacy or harm the environment. The ultimate effect of the work should be to the public good.
-
If the user meets the pre-conditions, then any errors in processing or the function’s result are the sole fault of the developer.
Example: The Bisection Method
Suppose we are given a continuous function \(f\), and we want to approximate a value \(r\) where \(f(r)=0\). While this can be a difficult problem in general, suppose that we can guess two points \(a\) and \(b\) (perhaps from a graph) where \(f(a)\) and \(f(b)\) have opposite signs. The four possible cases are shown below:
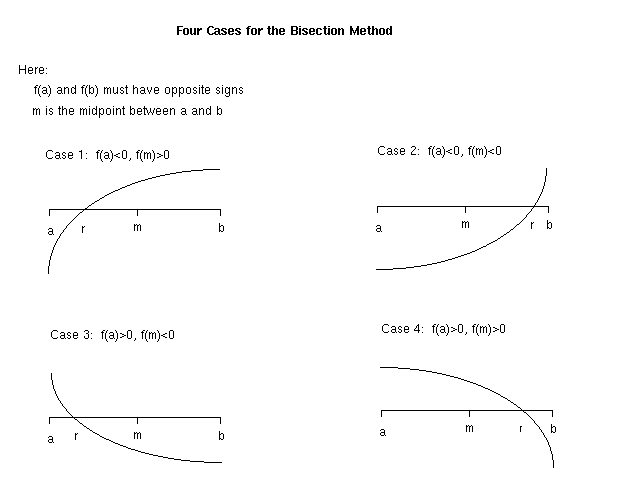
We are given \(a\) and \(b\) for which \(f(a)\) and \(f(b)\) have opposite signs. Thus, we can infer that a root \(r\) must lie in the interval \([a, b]\). In one step, we can cut this interval in half as follows. If \(f(a)\) and \(f(m)\) have opposite signs, then \(r\) must lie in the interval \([a, m]\); otherwise, \(r\) must lie in the interval \([m, b]\).
Finding Square Roots
As a special case, consider the function \(f(x) = x^2 - a\). A root of this function occurs when \(a = x^2\), or \(x = \sqrt a\). Thus, we can use the above algorithm to compute the square root of a non-negative number.
An implementation of square_root using this bisection method follows.
Note that the square_root function includes comments that follow a doxygen style;
doxygen is a tool that can generate formatted documentation from commented code.
/**
* Calculate the square root of a positive number.
*
* \param t The number whose square root must be found
* \returns an approximate square root of t
*/
double square_root(double t) {
double a, b, m; // desired root will be in interval [a,b] with midpoint m
double fa, fb, fm; // values f(a), f(b), f(m), resp., for f(x) = x^2 - t,
double accuracy = 0.0001; // desired accuracy of result
// Set up initial interval for the bisection method
a = 0;
b = (t > 2.0 ? 2.0 : t);
fa = a*a - t;
fb = b*b - t;
// Iterate interval shrinking until sufficiently small
while(b - a > accuracy){
// m is the midpoint of [a,b]
m = (a + b) / 2.0;
fm = m*m - t;
// Leave the loop if we have the exact root
if (fm == 0.0) break;
if ((fa * fm) < 0.0) {
// f(a) and f(m) have opposite signs
b = m;
fb = fm;
} else {
a = m;
fa = fm;
}
}
return t;
}
This code has implicit pre- and post-conditions: the value t must be positive for the method to work, and the result must be an approximately-correct square root of t.
To Test Pre-Conditions or Not?
Although the user of a function has the responsibility for meeting its pre-conditions, computer scientists continue to debate whether functions should check that the pre-conditions actually are met. Here, in summary, are the two arguments.
- Pre-conditions should always be checked as a safety matter; a function should be sufficiently robust that it will detect variances in incoming data and respond in a controlled way.
- Since meeting pre-conditions is a user’s responsibility, a developer should not add complexity to a function by handling unnecessary cases; further, the execution time should not be increased for a responsible user just to check situations that might arise by careless users.
Actual practice tends to acknowledge both perspectives in differing contexts. More checking is done when applications are more critical. As an extreme example, in software to launch a missile or administer drugs to a patient, software may perform extensive tests of correctness before taking an action—the cost of checking may be much less than the consequences resulting from unmet pre-conditions.
As a less extreme position, it is common to check pre-conditions once—especially when checking is relatively easy and quick, but not to check repeatedly when the results of a check can be inferred.
The assert function in C
At various points in processing, we may want to check that various pre-conditions or assertions are being met.
C’s assert utility serves this purpose.
The assert function takes a Boolean expression as a parameter.
If the expression is true, program execution continues.
However, if the expression is false, assert discovers the undesired condition, and regular execution is halted with an error message.
The assert utility should not be used for checking user input.
A failed assertion causes a program to exit, but we usually want to deal with invalid user input more gracefully than that.
Instead, assertions should be used to verify assumptions about the state of the program during development and/or debugging.
Example
For our square root example, two types of assertions initially come to mind.
- The
tparameter is supposed to be a positive number. Providing zero or a negative number violates the function’s pre-condition. - During processing, numbers a and b are supposed to be endpoints of an interval, over which the function \(f(x) = x^2 - t\) changes sign. The bisection method fails if \(f(a)\) and \(f(b)\) have the same sign.
Here we can see an updated version of square_root with two additions:
- Documented pre- and post-conditions in the function’s doxygen comment.
- An assertion in the function’s
whileloop to check the second condition above. Notice that the assertion includes a condition (fa * fb < 0that is and-ed with a string; this is a common “hack” you will see in C assertions. If the assertion fails (that is, the condition we expect to be true is actually false) the failure will print the entire condition, including this string message.
/**
* Calculate the square root of a positive number.
*
* \param t The number whose square root must be found
* \returns an approximate square root of t
*
* \pre t is greater than zero
* \post |m*m - t| <= accuracy
*/
double square_root(double t) {
double a, b, m; // desired root will be in interval [a,b] with midpoint m
double fa, fb, fm; // values f(a), f(b), f(m), resp., for f(x) = x^2 - t,
double accuracy = 0.0001; // desired accuracy of result
// Set up initial interval for the bisection method
a = 0;
b = (t > 2.0 ? 2.0 : t);
fa = a*a - t;
fb = b*b - t;
// Iterate interval shrinking until sufficiently small
while(b - a > accuracy){
assert(fa * fb < 0 && "x^2 - t must have opposite signs at a and b");
// m is the midpoint of [a,b]
m = (a + b) / 2.0;
fm = m*m - t;
// Leave the loop if we have the exact root
if (fm == 0.0) break;
if ((fa * fm) < 0.0) {
// f(a) and f(m) have opposite signs
b = m;
fb = fm;
} else {
a = m;
fa = fm;
}
}
return t;
}
If this function is run with the value 5 for t, the program stops abruptly, printing:
Assertion failed: (fa * fb < 0 && "x^2 - t must have opposite signs at a and b"), function square_root, file bisection.c, line 24
This version of the algorithm has a subtle error in it; the assertion has potentially helped us to identify it more easily. As it turns out, there is a subtle error in the section of code initializing the interval. After reading again through the comments establishing the variable values, can you isolate it? (If not, we will learn in another class to use a debugger that will allow us to probe the variables interactively while our program runs.)
Disabling assert Statements
Because assertions can take some time and effort to create but may cause problems during “normal” (i.e., non-debugging) executions of a program, they can be disabled by #defineing NDEBUG before assert.h is #included or (equivalently) including -DNDEBUG flag in the compile command.
When invoking the compiler directly, you could do this as follows.
clang -DNDEBUG -o bisection bisection.c
A “Testing” Frame of Mind
Once we know what a program is supposed to do, we must consider how we know whether it does its job. There are two basic approaches:
- Verification
- Develop a formal, mathematical proof that the program always does exactly what has been specified.
- Testing
- Run the program with a range of data, in each case checking the results with what we know to be correct.
Although a very powerful and productive technique, formal verification suffers from several practical difficulties:
- We must be able to specify formally all pre- and post-conditions, and this may require extensive development.
- Formal proof techniques require extensive development and are beyond the scope of this course.
- Formal verification typically assumes that compilers and runtime environments are correct, which is certainly not always the case.
Altogether, for many programs and in many environments, we often try to infer the correctness of programs through testing. However, it is only possible to test all possible cases for only the simplest programs. Even for our relatively simple program to find square roots, we cannot practically try all possible positive, double-precision numbers as input.
Our challenge for testing, therefore, is to select test cases that have strong potential to identify any errors. The goal of testing is not to show the program is correct—there are too many possibilities. Rather, the goal of testing is to locate errors. In developing tests, we need to be creative in trying to break the code; how can we uncover an error?
Choosing Testing Cases
As we have discussed, our challenge in selecting tests for a program centers on how to locate errors. Two ways to start look at the problem specifications and at the details of the code:
- Black-Box Testing
- The problem is examined to determine the logical cases that might arise. Test cases are developed without reference to details of code.
- White-Box Testing
- Code is examined to determine each of the possible conditions that may arise, and tests are developed to exercise each part of the code.
A list of potential situations together with specific test data that check each of those situations is called a test plan.
A Sample Test Plan
To be more specific, let’s consider how we might select test cases for the square-root function.
Black-box Testing of the Square-Root Program
Since we can choose any values we wish, we will choose values for which we already know the answer.Often we choose some small values and some large ones.
- Input: 0.25 (answer should be 0.5; \((1/2)^2\) is 1/4)
- Input: 9 (answer should be 3)
White-box Testing
We want to exercise the various parts of the code.
The program sets b to 2 when finding the square root of a small number, so we want to cover that case:
- Input: 0.25 (from above — value smaller than 1)
- Input: 1.44 (1.2 squared — value larger than 1, but smaller than 2)
Similarly, the program sets b to t for larger numbers, and we want to cover that case:
- Input: 9 (from above)
The main loop stops if the loop discovers the square root exactly, so we want to select cases that have this property:
- Input: 1 (should reach this result on the first iteration)
- Input: 16 (should reach this result when
bmoves from 16 to 8 to 4)
The main loop sometimes changes a and sometimes changes b, so we want input that guarantees we will check both of those code segments.
- Input: 0.25 (for numbers smaller than 1, the square root is larger than the number, so
awill have to move right in the loop) - Input: 9 (for numbers larger than 1, the square root is smaller than the number, so
bwill have to move left in the loop)
Putting these situations together, we seem to test the various parts of the code with these test cases:
- Input: 0.25
- Input: 1
- Input: 1.44
- Input: 9
- Input: 16
Each of these situations examines a different part of typical processing. More generally, before testing begins, we should identify different types of circumstances that might occur. Once these circumstances are determined, we should construct test data for each situation, so that our testing will cover a full range of possibilities.
Copyright © Charlie Curtsinger, Nicole Eikmeier, Priscilla Jimenez, and Dawn Nye
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
This work is derived from materials by Charlie Curtsinger, Nicole Eikmeier, Fernanda Eliott, Priscill Jimenez, Barbara Johnson, Titus Klinge, Dawn Nye, Peter-Michael Osera, Sam Rebelsky, John Stone, Henry Walker, and Jerod Weinman.
This website was built using Jekyll, Twitter Bootstrap, and the Bootswatch Cosmo Theme.