Coding Challenge 5: More sophisticated data science
- Assigned
- Friday, 3 October 2025
- Summary
- In this coding challenge we will work with imported data to solve more complex problems with lists.
- Collaboration
- You must work individually on this assignment. You may only consult members of the course staff for help.
Instructions
In this coding challenge, we’re going to work with the us zip codes data that we explored a little bit in a class lab. We’re going to be working with a much bigger version of the file, and it’s important that you only use with-file-chooser, and not with-file for this assignment. The reason has to do with availability of browser storage - if you try using with-file it’s very likely that your scamper instance will freeze up. Note that even if you use with-file-chooser, if your code prints the entire file to the screen, it may take quite a while and your browser may appear to freeze up. In our experience if you hit “wait”, it’ll finish eventually.
The full file can be downloaded here: us-zip-codes.csv
Recommendation: Go back to the lab from October 1 to get a smaller version of this table to test with pieces of your code. This will avoid the lag time mentioned previously.
We are providing you with starter code, CC5-template.scm. You should download this file and upload the given code to a new .scm file named data-science.scm.
You are required to document every procedure that you write using the documentation style of our course. Tests are optional, but likely helpful in determining if your code is working as desired.
At the top of your file, make sure to include your name, and any acknowledgements according to our collaboration policy. Now is a great time to review those collaboration policies.
Problem 1: Distance between cities
In this problem we’re going to work on finding the distance between two points on the globe as defined by their latitude and longitude. Note that when points are relatively near to each other, we can use a simple distance formula and treat the earth as flat. When points are farther away, the curve of the earth has a big impact on the distance so to be much more accurate we use the Haversine function, or the great circles distance.
Say we have two cities with their latitude and longitude stored as a pair in Scheme.
(define DesMoines (pair 41.672687 -93.572173))
(define Grinnell (pair 41.685324 -92.630258))
Part A
The latitude and longitude in this example (and in the us-zip-codes file) are in degrees, however we will need the values in radians. Write a procedure, deg->rad, which converts a value in degrees to radians according to the following formula.
radians = ( π * degrees ) / 180
The value of pi is available to you in scamper as pi.
> (deg->rad 41.5896)
> 0.7258754545874336
Part B
Now that we have a way to convert coordinates to radians, we can use the Haversine function which will return the distance in kilometers. Here is how the function works. Say we have two pairs of coordinates in radians.
(define coordinate1 (pair lat1 lon1))
(define coordinate2 (pair lat2 lon2))
Then we can use calls to the built in procedures of sin, cos, and atan for the trigonometric functions sine, cosine, and arctan. The following is written in common mathematical notation, you’ll need to translate it to work in Scheme. In the formula, 6371 is the average radius of the earth.
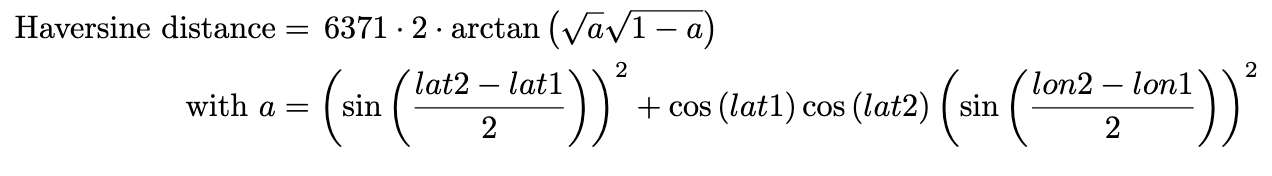
Write a procedure, haversine, to compute the haversine distance between two coordinates. Remember that the coordinates you use in the above formula need to be in radians.
> (haversine DesMoines Grinnell)
> 78.23482791072104
Part C
Find the 5 closest entries to Des Moines in the zip code data. There are quite a few moving parts to this, so we highly suggest using decomposition and very careful documentation.
Hint: One important thing you’ll need to do is figure out how to remove some entries in the data which do not have valid entries for longitude and/or latitude. Those entries end up loading into Scamper as "" (the empty string).
In this problem you should provide your code to get your answer, as well as a comment containing your answer.
Part D
If someone asked you for the five closest cities to Des Moines, you would not expect them to say
(("10123" 40.751489 -73.990537 "New York" "NY" "New York")
("21123" 38.974203 -76.594942 "Pasadena" "MD" "Anne Arundel")
("VA" "23123" 37.563225 -78.53643 "New Canton" "Buckingham")
("16123" 40.813208 -80.199126 "Fombell" "PA" "Beaver")
("30123" 34.244179 -84.845684 "Cassville" "GA" "Bartow"))
In part, that’s because those aren’t the five closest cities. But it’s also that all we really want is the city and state. That is, we’d like to see a result more like the following.
(list "New York, NY" "Pasadena, MD" "New Canton, VA" "Fombell, PA" "Cassville, GA")
Write a procedure, place-name, that takes one of those entries as a parameter and returns the place name in the form "CITY, STATE".
(define place-name
{??})
(place-name (list "10123" 40.751489 -73.990537 "New York" "NY" "New York"))
"New York, NY"
Submission guidelines
Submit data-science.scm to Gradescope.
Grading rubric
In grading your submission, we will look for the following at each level. Note that if a criteria does not pass a lower level, we will likely not check for criteria at the higher levels. We may also identify other characteristics that move your work between levels.
You should read through the rubric and verify that your submission meets the rubric.
Redo or above
Submissions that lack any of these characteristics will get an I.
[] Includes the specified file (correctly named).
[] Includes an appropriate header on the file that indicates the course, author, acknowledgements, etc.
[] Acknowledges appropriately.
[] Code runs in scamper.
Meets expectations or above
Submissions that lack any of these characteristics but have all of the prior characteristics will get an R.
[] Code is well-formatted with appropriate names and indentation.
[] Code submission is organized with comments to indicate the start of new problems.
[] All Gradescope tests pass for Problem 1A.
[] All Gradescope tests pass for Problem 1B.
[] All Gradescope tests pass for Problem 1C.
[] All Gradescope tests pass for Problem 1D.
[] Documentation in the 151 style is included for all code, and contains correct information.
Exemplary / Exceeds expectations
Submissions that lack any of these characteristics but have all of the prior characteristics will get an M.
[] All code is exceptionally organized and easy to read, through the use of comments (to explain the purpose of different pieces of the code), decomposition, and highly intuitive naming choices.
[] Helper functions are used in a way to avoid replicating code in multiple places.